In my early days as a ruby programmer, I used to always look for good examples through which I could understand Blocks and lambdas in Ruby. I did understand them after some research but I guess the connectivity of a real life e.g., was somewhere missing to help me remember how can one use them always. That's how I relate to this post and here's an attempt to help drive home the concept of Ruby lambdas and blocks for beginners at least to some extent. This has been tried and tested on Ruby-1.9.3p484
Here we'll try to explore how one could leverage the power of Blocks and Lambdas to make your code look more clean by refactoring one's code along the lines of better adhering to the Don't Repeat Yourself(DRY) principle.
Below is the original code of a singly linked list before any refactoring is done -
Refactoring 1 -
Problem Context - Methods list_count(returns the number of linked list elements) and list_elements(list the linked list elements) basically traverse through the entire linked list including the last node and both have a duplicated linked list traversal condition @current_pointer != nil .
To do - Remove the above duplication
Solution - Blocks to the Rescue!
Adding blocks - If you have a look at the list_elements and the list_count methods they have duplicated for the lines 35-39(excepting line 37) and 45-49(excepting line 48). This doesn't adhere to the DRY principle and hence requires further refactoring.
Below is a screen shot of what gets changed. You can have a look at this commit which shows the full modified version of the code as part of the first refactoring.

Below is a screen shot of what gets changed. You can have a look at this commit which shows the full modified version of the code as part of this refactoring.

End Result - More concise solution adhering to the DRY principle.
Credits to the Pickaxe book by Dave Thomas for the learnings and to Avinasha for recommending this book.
P.S: This code has scope for further refactoring. I have just taken two sample use cases in an attempt to try and explain Blocks and Lambdas in Ruby.
Here we'll try to explore how one could leverage the power of Blocks and Lambdas to make your code look more clean by refactoring one's code along the lines of better adhering to the Don't Repeat Yourself(DRY) principle.
Below is the original code of a singly linked list before any refactoring is done -
Problem Context - Methods list_count(returns the number of linked list elements) and list_elements(list the linked list elements) basically traverse through the entire linked list including the last node and both have a duplicated linked list traversal condition @current_pointer != nil .
To do - Remove the above duplication
Solution - Blocks to the Rescue!
Adding blocks - If you have a look at the list_elements and the list_count methods they have duplicated for the lines 35-39(excepting line 37) and 45-49(excepting line 48). This doesn't adhere to the DRY principle and hence requires further refactoring.
Below is a screen shot of what gets changed. You can have a look at this commit which shows the full modified version of the code as part of the first refactoring.
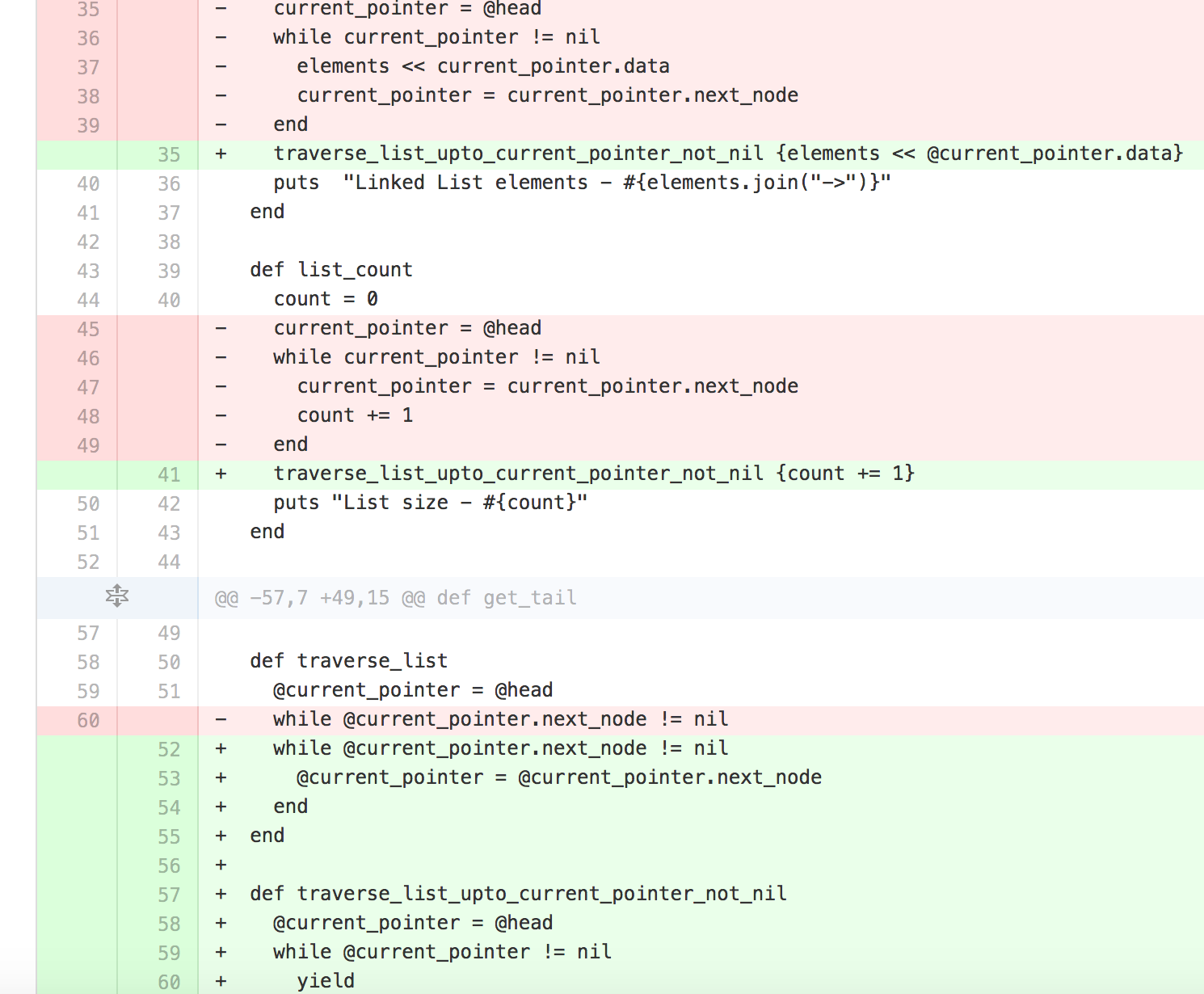
End Result - Lesser lines of code.
Refactoring 2 -
Problem Context - If you observe carefully, you'd find the other traverse_list method has the linked list traversal condition @current_pointer,next_node != nil and they are used to add a
new node to the linked list at the end through the add_in_end method
and the same is used in the get_tail method to get the last node. With the above condition, the current pointer stops at the last node but on the other hand with the condition @current_pointer != nil used by the list_count and list_elements method use the current pointer goes past the last node to satisfy the specific method requirement. The question now is, can we still remove any further duplication? The answer is yes.
Solution - Introducing Lambdas because we can't use past multiple blocks to methods in Ruby 1.9 . Read this link for more info.
End Result - More concise solution adhering to the DRY principle.
Credits to the Pickaxe book by Dave Thomas for the learnings and to Avinasha for recommending this book.
P.S: This code has scope for further refactoring. I have just taken two sample use cases in an attempt to try and explain Blocks and Lambdas in Ruby.